Java Stream 流式编程
什么是 Stream
Stream 流式 API 是 JDK1.8 后才出现的,它位于 java.util.stream 包中
说到 Stream 就容易想到 I/O Stream,但是事实上这个 Stream 与其是完全不同的概念,在 Java8 中,得益于 Lambda 所带来的函数式编程,引入了一个全新的 Stream 概念,用于解决已有集合类既有的弊端。
- Stream API提供了一套新的流式处理的抽象序列;
- Stream API支持函数式编程和链式操作;
- Stream可以表示无限序列,并且大多数情况下是惰性求值的。
而所谓的流式思想类似于工厂车间的生产流水线,与 I/O Stream 无关,所以实际上应该称其为 “流水线工具类”
几乎所有的集合都支持直接或间接的遍历操作。而当我们需要对集合中的元素进行操作的时候,最典型的就是集合遍历
public class Demo {
public static void main(String[] args) {
//创建一个List集合,存储姓名
List<String> list = new ArrayList<>();
Collections.addAll(list,"张无忌","小明","赵敏","张强","张三丰","张三");
//对list集合中的元素进行过滤,只要以张开头的元素,存储到一个新的集合中
List<String> listA = new ArrayList<>();
for (String s : list) {
if (s.startsWith("张")) {
listA.add(s);
}
}
//对listA集合中的元素进行过滤,只要姓名长度为3的元素,存储到一个新的集合中
List<String> listB = new ArrayList<>();
for (String s : listA) {
if (s.length() == 3) {
listB.add(s);
}
}
//最后再遍历
listB.forEach(System.out::println);
}
}
使用 Stream 流的方式,遍历集合,对集合中的数据进行过滤
public class Demo {
public static void main(String[] args) {
//创建一个List集合,存储姓名
List<String> list = new ArrayList<>();
Collections.addAll(list, "张无忌","小明","赵敏","张强","张三丰","张三");
//使用流(链式调用)
list.stream()
.filter(name -> name.startsWith("张"))
.filter(name -> name.length() == 3)
.forEach(System.out::println);
}
}
可以发现简洁了很多
流的特点(装饰器模式)
参考资料 廖雪峰老师的 使用Stream
1、它可以 “存储” 有限个或无限个元素。这里的存储打了个引号,是因为元素有可能已经全部存储在内存中,也有可能是根据需要实时计算出来的。
// 不用管 createNaturalStream 这个方法是怎么实现的,总之就是取得一个自然数流
// 如下打印出了前100个自然数的平方
Stream<BigInteger> naturals = createNaturalStream();
naturals.map(n -> n.multiply(n)) // 1, 4, 9, 16, 25...
.limit(100)
.forEach(System.out::println);
2、真正的计算通常发生在最后结果的获取时,也就是惰性计算。(其实有点像装饰器模式,但是这个是在取得结果时才进行计算)
Stream<BigInteger> naturals = createNaturalStream(); // 不计算
Stream<BigInteger> s2 = naturals.map(BigInteger::multiply); // 不计算
Stream<BigInteger> s3 = s2.limit(100); // 不计算
s3.forEach(System.out::println); // 计算
惰性计算的特点是:一个 Stream 转换为另一个 Stream 时,实际上只存储了转换规则,并没有任何计算发生。
// 所以一般使用链式调用
createNaturalStream()
.map(BigInteger::multiply)
.limit(100)
.forEach(System.out::println);
即,所有操作都是链式调用,一个元素只迭代一次
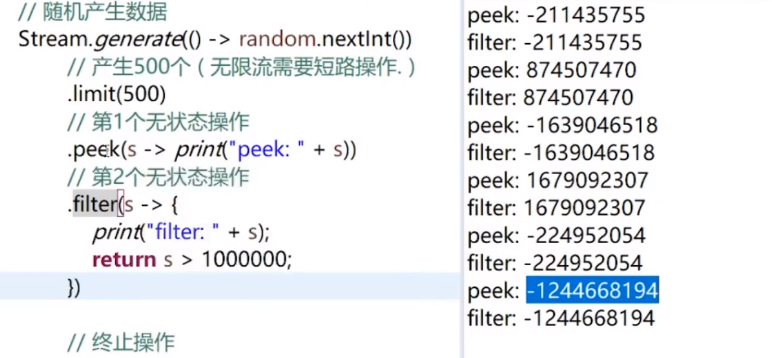
如图,它是每个节点依次执行这条链上的操作
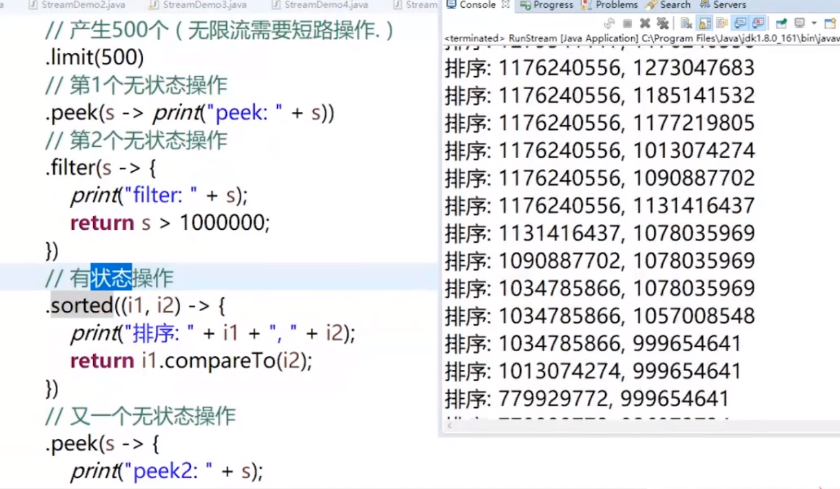
但是注意,有状态操作会对上面的链进行一个汇总:
获取 Stream 的方式
Stream 是 Java8 新加入的最常用的流接口(不是函数式接口)
获取一个流有以下方法
- 所有的
Collection集合都可以通过stream默认方法获取流 Stream接口的静态方法of可以获取数组对应的流
使用 Collection 集合的 stream 方法取得
public class Demo {
public static void main(String[] args) {
//把集合转换为Stream流
//list流
List<String> list = new ArrayList<>();
Stream<String> stream1 = list.stream();
//Set集合
Set<String> set = new HashSet<>();
Stream<String> stream2 = set.stream();
//HashMap的集合,这个比较特殊不能直接获取
Map<String,String> map = new HashMap<>();
//获取键,存储到一个Set集合中
Set<String> keySet = map.keySet();
Stream<String> stream3 = keySet.stream();
//获取值,存储到一个Collection集合中
Collection<String> values = map.values();
Stream<String> stream4 = values.stream();
//获取键值对 键与键的映射关系 entrySet
Set<Map.Entry<String, String>> entries = map.entrySet();
Stream<Map.Entry<String, String>> stream5 = entries.stream();
/*
这个Entry用法如下
entry.getKey()
entry.getValue()
*/
}
}
使用 Stream 接口的 of 方法取得,这个 of 方法传递一个可变参数
public class Demo {
public static void main(String[] args) {
Stream<Integer> integerStream = Stream.of(1, 2, 3, 4, 5, 6);
// 可变参数可以传递数组
Integer[] arr = {1, 2, 3, 4, 5, 6};
Stream<Integer> stream = Stream.of(arr);
String[] arr2 = {"s","b","s","n"};
Stream<String> stream2 = Stream.of(arr2);
}
}
map 映射新值
如果需要将流中的元素映射到另一个流中,可以使用 map 方法,例如把 String 映射成 Integer
public class Demo {
public static void main(String[] args) {
Stream<String> stream = Stream.of("1", "2", "3", "4", "5", "6");
stream.map(Integer::parseInt).forEach(System.out::println);
}
}
这个 map 可用使用
stream.map(Integer::parseInt).collect(Collectors.toList()
来返回一个 List
count 计数
统计个数:正如集合类 Collection 当中的 size 方法一样,流提供 count 方法来数一数其中的元素个数
public class Demo {
public static void main(String[] args) {
System.out.println(Stream.of("1", "2", "3", "4", "5", "6").count());
}
}
注意:用了这个方法之后就无法再继续链式调用了,因为这个方法返回的是
long类型
limit 截取
limit 方法可以对流进行截取(只取用前 n 个)
public class Demo {
public static void main(String[] args) {
Stream.of("1", "2", "3", "4", "5", "6").limit(3).forEach(System.out::println);
}
}
skip 跳过元素
这个方法与上面那个方法刚好相反,该方法表示:跳过前几个元素,可以使用 skip 方法去获取一个截取后的流
public class Demo {
public static void main(String[] args) {
Stream.of("1", "2", "3", "4", "5", "6").skip(3).forEach(System.out::println);
}
}
filter 过滤器
语法:
// 传入一个断言接口,即能产生 boolean 结果的 Lambda
Stream<T> filter(Predicate<? super T> predicate);
- 如果参数 Lambda 产生了 true 值,则要元素;
- 如果产生了false,则不要这个元素。
public class StreamFilter {
public static void main(String[] args) {
ArrayList<Integer> list1 = new ArrayList<>();
list1.add(90);
list1.add(85);
list1.add(70);
//过滤出大于80的数字
Stream<Integer> Stream1 = list1.stream().filter((Integer num) ->{
boolean b = num > 80;
return b;
});
Stream<Integer> Stream2 = list1.stream().filter(num ->{
boolean b = num > 80;
return b;
});
Stream<Integer> Stream3 = list1.stream().filter( num ->{
return num > 80;
});
Stream<Integer> Stream4 = list1.stream().filter( num -> num > 80);
// 使用 filter 取得新 List
List<String> result = lines.stream() // convert list to stream
.filter(line -> !"ricky".equals(line)) // we dont like ricky
.collect(Collectors.toList()); // collect the output and convert streams to a List
}
}
concat 合并流
这个方法是静态方法,如果有两个流,希望合并成为一个流
public class Demo {
public static void main(String[] args) {
Stream<String> streamA = Stream.of("1", "2", "3", "4", "5", "6").filter(x->Integer.parseInt(x)>3);
Stream<String> streamB = Stream.of("1", "2", "3", "4", "5", "6").filter(x->Integer.parseInt(x)<=2);
Stream.concat(streamA,streamB).forEach(System.out::println);
}
}
groupBy 分组
参考资料 java~集合分组groupby的实现
在 Stream 流里面如何实现像 SQL 的那种分组写法呢?
对于数据聚合来说,分组操作是很常见的,在 .net 里有 lambda 和 linq,而在 java 里也有 lambda
Map<String, List<Product>> groupByPriceMap =
products.stream().collect(Collectors.groupingBy(Product::getName));
products = new ArrayList<>();
for (Map.Entry<String, List<Product>> str : groupByPriceMap.entrySet()) {
List<Item> items = new ArrayList<>();
for (Product product : str.getValue()) {
items.addAll(product.getItems());
}
products.add(new Product(str.getKey(), "", items));
}
多条件分组的实现
Function<Product, List<Object>> compositeKey = personRecord ->
Arrays.asList(personRecord.getName(), personRecord.getCode());
Map<Object, List<Product>> map =
products.stream().collect(Collectors.groupingBy(compositeKey));
使用方式二(Map 转成其它类型)
List<UrlAndNameDo> permissions = permissionMapper.getAllPermissions();
// 上面那行代码不用管,总之就是取得了一个 List 这个 UrlAndNameDo 内部就包含了 url 和 ename 两个属性
Map<String, List<String>> collect = permissions.stream()
.collect(Collectors.groupingBy(UrlAndNameDo::getEname)).entrySet().stream()
.collect(Collectors.toMap(
Map.Entry::getKey,
e -> e.getValue().stream().map(UrlAndNameDo::getUrl).collect(Collectors.toList())
));
peek Debug 工具方法
peek 方法接收一个 Consumer 的入参。了解λ表达式的应该明白 Consumer的实现类 应该只有一个方法,该方法返回类型为 void。
Stream<T> peek(Consumer<? super T> action);
说明,这里的 peek 并不会传递到下一个流,所以它主要被用在 debug 用途。使用例
Stream.of("one", "two", "three", "four")
.filter(e -> e.length() > 3)
.peek(e -> System.out.println("Filtered value: " + e))
.map(String::toUpperCase)
.peek(e -> System.out.println("Mapped value: " + e))
.collect(Collectors.toList());
sorted 排序
排序分为自然排序和定制排序
自然排序:Comparable 定制排序:Comparator
inputCollection.stream()
.map(e -> new Element(e.id, e.color))
.sorted(Comparator.comparing(Element::getId))
.collect(Collectors.toList());
并行流 😎
调用 parallel 产生并行流
// IntStream 自带的工具类
IntStream.range(1, 100)
.parallel()
.peek(x -> {
try {
// 暂停一秒打印
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
})
// 这个 count 是终止操作(每个 Stream 操作都得有一个终止操作)
.count();
查看结果会发现打印结果是乱序的,因为是并行操作
但是如果即使用并行又使用串行,结果按照最后一个决定使用串行还是并行(sequential 产生一个串行流)
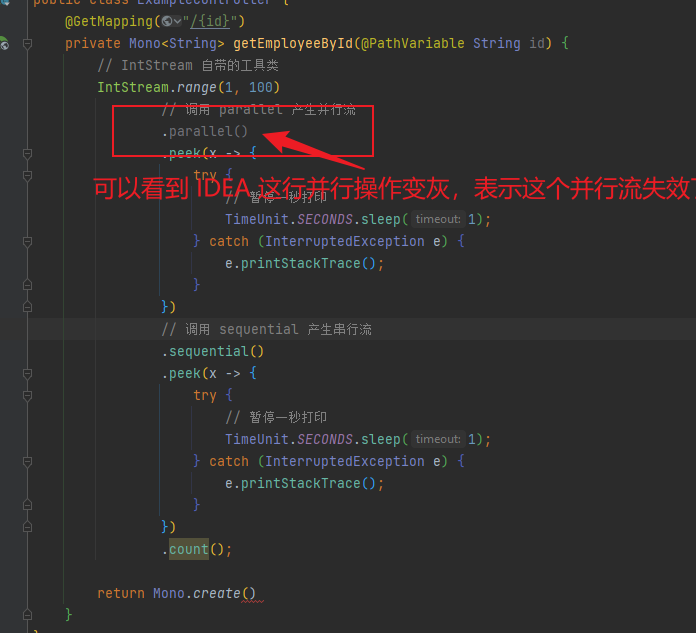
注意,这里的并行流使用的是系统自带的线程池,如果想使用自己的线程池可以如下这样
// 创建一个线程池
ForkJoinPool pool = new ForkJoinPool(20);
// 把自己的并行任务放在线程池里面
pool.submit(() -> IntStream.range(1, 100)
// 调用 parallel 产生并行流
.parallel()
.peek(x -> {
try {
// 暂停一秒打印
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
})
.count());
// 执行完任务关闭线程池
pool.shutdown();
// 这里加个等待,免得任务直接关闭
synchronized (pool) {
try {
pool.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
收集器
对流中元素执行一个可变汇聚操作。是一个 终止操作。
比如:将流中的元素放入到一个 List 集合当中,将流中的元素进行分组、分区,求和等等操作。接受一个收集器 Collector 对象。Collector 收集器下面会详细介绍。下面举几个例子:
// 例如从 Student 取得年龄
students.stream().map(Student::getAge).collect(Collectors.toList());
// 根据 task 的类型进行分组
private static Map<TaskType, List<Task>> groupTasksByType(List<Task> tasks) {
return tasks.stream().collect(groupingBy(Task::getType));
}
数组转成 List
Integer [] myArray = { 1, 2, 3 };
List myList = Arrays.stream(myArray).collect(Collectors.toList());
//基本类型也可以实现转换(依赖 boxed 的装箱操作)
int [] myArray2 = { 1, 2, 3 };
List myList = Arrays.stream(myArray2).boxed().collect(Collectors.toList());